DIAN.AFRIAL
#1 Case Study: We Love Photos: A Field Guide to a Modern TypeScript Monorepo
02 Jun 2026 | 19:48
A casual, code-grounded walkthrough of how a photo-search platform is put together with Turborepo, Next.js, Hono, Bun, and a healthy obsession with UX details.
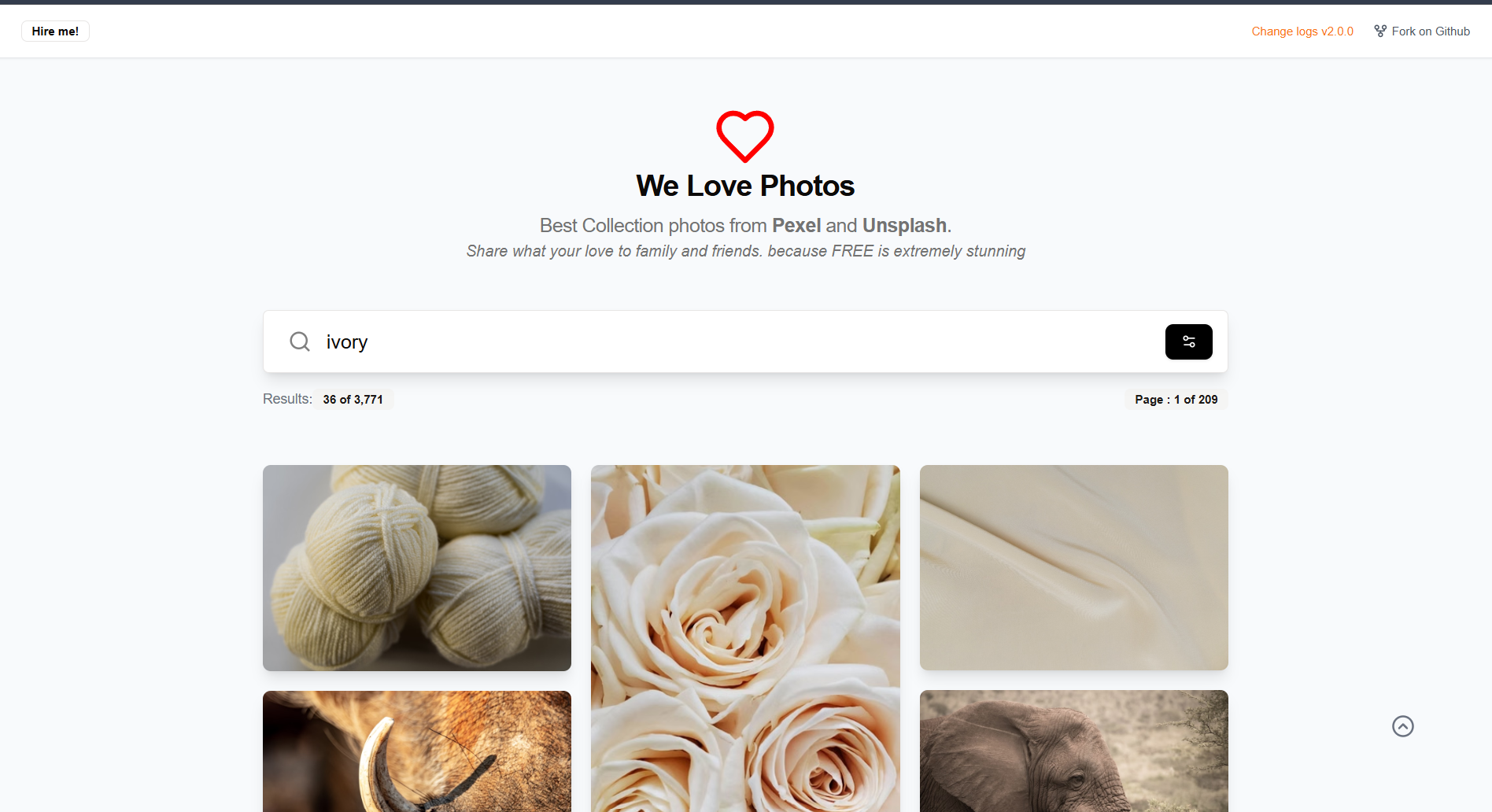
"We Love Photos" is a photo discovery (and in-browser AI background-removal) app. Under the hood it's a pnpm + Turborepo monorepo with two apps — a Next.js 15 frontend and a Hono.js API server — plus three shared packages (db, validators, utils). The web app ships as a static export to Vercel; the server runs on Bun during development and deploys to Cloudflare Workers via Wrangler. On the frontend, search is debounced, paginated with useInfiniteQuery, and rendered through a blurhash-backed masonry grid. On the backend, the server follows a tidy Domain-Driven Design layering so controllers, services, and repositories each have one job.
Let's take it apart.
Before you read the article please take a look my open source repository : https://github.com/agilworld/we-love-photos-v2 and land the page at https://welovephotos.dianragil.com
1. The Big Picture: One Repo, Many Moving Parts
Everything lives under one roof thanks to a pnpm workspace:
# pnpm-workspace.yaml
packages:
- "apps/*"
- "packages/*"
That gives us this layout:
we-love-photos-app/
├── apps/
│ ├── web/ # Next.js 15 frontend (static export → Vercel)
│ └── server/ # Hono.js API (Bun dev, Cloudflare Workers prod)
├── packages/
│ ├── db/ # Drizzle ORM schemas + Turso (libSQL) client
│ ├── validators/ # Zod validation schemas
│ └── utils/ # Shared utilities (cn, chunks2Arr, uniqueBy)
├── turbo.json
└── pnpm-workspace.yaml
Turborepo is the conductor. turbo.json defines tasks (build, dev, lint, test, deploy) and, crucially, encodes their dependencies:
"build": {
"dependsOn": ["^build"],
"outputs": [".next/**", "dist/**", ".wrangler/**", "!.next/cache/**"]
}
That ^build is the magic — it says "build my dependencies before building me." So when you run pnpm build, the shared packages (db, validators, utils) are built before web and server consume them. You get caching, parallelism, and a sane build order for free.
One root command runs the whole show in dev:
pnpm dev # boots web (3012) and server (3010) together
The shared packages are referenced as plain workspace deps, e.g. in apps/server/package.json:
"@welovephotos/db": "workspace:*",
"@welovephotos/validators": "workspace:*",
"@welovephotos/utils": "workspace:*"
This is the whole point of the monorepo: the server and the web app can both lean on the same db package, the same Zod validators, and the same helpers — no copy-paste, no drift.
2. The Web App: Next.js, Static Export, Off to Vercel
apps/web is a Next.js 15 / React 19 app with Tailwind, Shadcn/UI, Zustand, TanStack Query, and Transformers.js (for the in-browser AI background removal). The interesting deployment choice is in next.config.ts:
const nextConfig: NextConfig = {
output: "export", // fully static
images: {
unoptimized: true,
remotePatterns: [
/* pexels, unsplash */
],
},
};
output: "export" means Next spits out a purely static site into apps/web/out/. There's no Node server involved at runtime on the web side — it's just HTML/CSS/JS plus client-side data fetching. That makes it a perfect fit for Vercel's static hosting (and explains why all the "real" data work happens client-side via fetch, which we'll get to).
Because it's statically exported, the webpack config also does a little surgery to keep Node-only AI deps (sharp, onnxruntime-node) out of the browser bundle — aliasing them to false and remapping node:* protocols so Transformers.js can run in the browser without breaking the build.
3. The Server: Hono.js, Bun for Dev, Cloudflare Workers for Prod
This is where the deployment story gets genuinely fun, because the same Hono app runs on two different runtimes depending on the phase of life.
The app itself
src/index.ts is a tiny, framework-clean entry point:
const app = new Hono<{ Bindings: Env }>();
app.use("*", cors({ origin: (c) => c.env?.CORS_ORIGIN || "..." /* ... */ }));
app.route("/v1/api", photoRoutes);
app.get("/", (c) =>
c.json({ message: "We Love Photos API Server", status: "running" }),
);
export default app;
Hono is web-standard based (it speaks the Request/Response/fetch shape), which is exactly why it can hop between runtimes. Note the Bindings typing — Hono lets you type the env bindings that the runtime injects (Cloudflare Workers passes env automatically; in Node/Bun it comes from process.env).
Dev mode: Bun (fast and hot)
"dev": "bun --hot src/serve.ts"
serve.ts is a minimal Node-style adapter:
import app from "./index";
const port = parseInt(process.env.PORT || "3010", 10);
export default { fetch: app.fetch, port };
So during development you get Bun's instant startup and --hot reloading on port 3010. Super snappy local loop.
Production: Cloudflare Workers via Wrangler
For prod, the same code is deployed to the edge with Wrangler:
"build": "bun build ./src/index.ts --outdir=dist --minify --target=bun",
"deploy": "wrangler deploy"
And wrangler.toml wires it to a Worker:
name = "welovephotos-server"
main = "src/index.ts"
compatibility_date = "2024-01-01"
compatibility_flags = ["nodejs_compat"]
workers_dev = true
[vars]
TURSO_CONNECTION_URL = "(copy paste turso connection here)"
CORS_ORIGIN = "(the website url come from)"
So the mental model is: write once in Hono, develop at light speed with Bun, ship to Cloudflare's edge network with a single wrangler deploy. The nodejs_compat flag keeps things like the libSQL client happy in the Workers runtime.
⚠️ Real-world note: if you copy this pattern, secrets should go in Wrangler secrets (
wrangler secret put) rather than[vars]. The architecture here is sound; keep tokens out of committed config.
Anyway, if you want to deploy to VPS cloud with Docker you must set to run build with bun.js and using serve.ts instead of run index.ts. I recommend you using bun runtime with docker in cloud vps rather than using Cloudflare Workers.
4. Search, Done Right: useDebounce + useInfiniteQuery
The search experience is the heart of the web app, and it's a nice study in not hammering your APIs. The flow lives in features/search/:
SearchBar.tsx holds the raw input and only renders the grid once the user has typed more than 2 characters:
{
search.length > 2 ? (
<PhotoGrid keyword={search} />
) : (
<DefaultPhotoPlaceholder />
);
}
Inside PhotoGrid.tsx, two optimizations stack:
a) Debounce — don't search on every keystroke.
const resultQuery = useDebounce(keyword, 300); // 300ms settle time
The useDebounce hook is wonderfully small:
export default function useDebounce(value: any, timeout: number) {
const [debouncedValue, setDebouncedValue] = useState(value);
useEffect(() => {
const timer = setTimeout(() => setDebouncedValue(value), timeout);
return () => clearTimeout(timer);
}, [value, timeout]);
return debouncedValue;
}
Every keystroke resets the timer; only when the user stops typing for 300ms does the value propagate and trigger a query. Type "tiger" fast and you get one request, not five.
b) Infinite query — paginate cleanly with a 60s cache.
const { data, fetchNextPage, hasNextPage, isFetchingNextPage } =
useInfiniteQuery<PhotoRepositoryList>({
queryKey: photosKeys.search(
resultQuery,
undefined,
perPage,
color,
orientation,
),
queryFn: ({ pageParam = 1 }) =>
searchQueryPhotos({
/* ... */
}),
initialPageParam: 1,
getNextPageParam: (lastPage) => {
const currentPage = lastPage.page;
const totalPages = lastPage.total_pages;
return currentPage < totalPages ? currentPage + 1 : undefined;
},
enabled: resultQuery.length > 2,
staleTime: 60000, // <-- 60 seconds
placeholderData: keepPreviousData, // <-- no flash of empty state
});
A few details worth calling out:
staleTime: 60000— results are considered fresh for a minute. Flip filters or re-render and TanStack Query serves cached data instead of refiring requests. The 60s window is exactly right for a search UI where people browse back and forth.placeholderData: keepPreviousData— while a new search is loading, the old results stay on screen instead of vanishing. Subtle, but it kills the jarring "blank → results" flicker.enabled: resultQuery.length > 2— a second guard so we never query on 1–2 character stubs (the SearchBar guards too; belt and suspenders).perPage = 18with manual "Load more" pagination viafetchNextPage.
The accumulated pages are flattened and reshaped for the grid:
const photos = useMemo(
() => data?.pages.flatMap((page) => page.results) ?? [],
[data],
);
5. Multi-Source Fetch with Promise.allSettled
Here's a genuinely elegant bit. A single search hits two sources in parallel — the Pexels API and the project's own Hono server (which queries the Unsplash Lite dataset in Turso) — and it must keep working even if one of them face-plants.
libs/api/photos.ts:
const [pexel, serverResult] = await Promise.allSettled([
pexelSearchPhotosApi(queryKey),
serverSearchPhotosApi(
query ?? "",
per_page ?? 18,
((page ?? 1) - 1) * (per_page ?? 18),
),
]);
const photoObjList = new PhotoRepositoryList();
if (pexel.status === "fulfilled") {
photoObjList.setIteratorPhotoPexel(pexel.value);
}
if (serverResult.status === "fulfilled") {
photoObjList.setIteratorPhotoServer(serverResult.value);
}
return photoObjList;
Why allSettled and not all? With Promise.all, one flaky API would tank the entire search. allSettled waits for both, then you only fold in the ones that actually succeeded. Pexels down? You still get server results. Server slow? You still get Pexels. The user always gets something, and the merge happens through a PhotoRepositoryList that normalizes both shapes into one common PhotoResult type.
This is the textbook case for allSettled: independent calls where partial success is still valuable.
6. Image Loading That Doesn't Make Eyes Hurt: Blurhash
Loading a grid of photos naively means a parade of empty boxes snapping into images. "We Love Photos" avoids this with Blurhash — a compact string (~20–30 chars) that encodes a blurry placeholder, decoded client-side into a preview image.
The decode path (libs/image/decodeBlurhash.ts):
export function blurhashToDataUrl(
hash: string,
width: number,
height: number,
punch = 1,
) {
if (typeof window === "undefined") return "";
const w = Math.min(32, width || 32);
const h = Math.min(32, height || 32);
const pixels = decode(hash, w, h, punch); // → raw pixel data
const canvas = document.createElement("canvas");
// ...draw pixels to canvas, return as PNG data URL
return canvas.toDataURL("image/png");
}
Decoding is cheap but not free, so there's a memoization layer (blurhashCache.ts) keyed by hash:widthxheight:
const cache = new Map<string, string>();
export function getCachedBlurhash(hash, w, h) {
const key = `${hash}:${w}x${h}`;
let url = cache.get(key);
if (!url) {
url = blurhashToDataUrl(hash, w, h);
if (url) cache.set(key, url);
}
return url;
}
And the BlurHashImage component orchestrates the visual handoff with a two-phase state machine:
const [phase, setPhase] = useState<"buffer" | "ready">("buffer");
// blurhash placeholder sits behind the real <img>
// on real image's onLoad → setPhase("ready") → cross-fade opacity
The placeholder is rendered as a background layer; the real <img> (with loading="lazy" and decoding="async") sits on top, fading in on onLoad. The result: users see a colored, recognizable smudge instantly, and a smooth crossfade to the full-res shot — no popping, no layout shift (the container uses aspectRatio: width / height to reserve space).
The server even stores a blurHash column per photo, so the Unsplash-Lite-sourced images come with their placeholder baked into the data.
7. The Masonry Grid (Not Just CSS Columns)
A photo grid with wildly varying aspect ratios needs masonry — and this project implements it in JS rather than relying purely on CSS columns (which read top-to-bottom per column and awkwardly split). The core algorithm lives in libs/utils.ts:
export function masonryColumns<T extends { width: number; height: number }>(
items: T[],
columnCount: number,
): T[][] {
const columns: T[][] = Array.from({ length: columnCount }, () => []);
const heights = new Array(columnCount).fill(0);
const normalizeHeight = (item: T) =>
!item.width || item.width === 0 ? 1 : item.height / item.width;
for (const item of items) {
const shortestColumnIndex = heights.indexOf(Math.min(...heights));
columns[shortestColumnIndex].push(item);
heights[shortestColumnIndex] += normalizeHeight(item);
}
return columns;
}
It's the classic "greedy shortest column" approach: for each photo, drop it into whichever column is currently shortest (measured by aspect-normalized height), then update that column's running height. Balanced columns, minimal gaps.
The column count is responsive, decided by a hook:
// useColumnCount.ts
if (width < 640) → 1 column
else if (width < 1024) → 2 columns
else → 3 columns
And in PhotoGrid.tsx, the photos are chunked into columns only when needed:
const newFormData = useMemo(() => {
if (photos.length === 0) return [];
if (columnCount === 1) return chunks2Arr(photos, 1); // mobile: simple list
return masonryColumns(photos, columnCount); // desktop: balanced masonry
}, [photos, columnCount]);
The grid rendering itself is wrapped in a memo'd component with a hand-written arePropsEqual comparator, so the heavy column list only re-renders when the actual photo set or layout genuinely changes — not on every parent re-render. That's a thoughtful perf touch.
8. The Server's Secret Weapon: Domain-Driven Layering
Now back to the backend. The Hono server is organized by domain (src/photos/), and within that domain it layers cleanly:
photos/
├── photo.model.ts # TypeScript types (PhotoRow, SearchResponse, SearchRequest)
├── photo.schema.ts # (delegates to @welovephotos/validators — Zod)
├── photo.repository.ts # pure data access via Drizzle
├── photo.service.ts # business logic / orchestration
└── photo.controller.ts # HTTP handling
Each layer has exactly one responsibility:
| Layer | Responsibility |
|---|---|
| Model | Type definitions for the Photo domain |
| Schema | Runtime validation (Zod, from the shared validators package) |
| Repository | Only talks to the DB (Drizzle). No business logic. |
| Service | Orchestrates repositories, transforms data into domain shapes |
| Controller | Parses the HTTP request, validates input, calls the service, shapes the HTTP response |
Here's how a real request flows end-to-end.
Controller (photo.controller.ts) — HTTP in, HTTP out:
photoRoutes.get("/search", async (c) => {
const keyword = c.req.query("keyword");
if (!keyword)
return c.json(
{ success: false, error: "keyword query parameter is required" },
400,
);
const parsed = searchQuerySchema.safeParse({ keyword, limit, offset }); // Zod
if (!parsed.success)
return c.json({ success: false, error: parsed.error.flatten() }, 400);
try {
const service = new PhotoService(c.env);
const result = await service.searchByKeyword(parsed.data);
return c.json({ success: true, data: result });
} catch (error) {
return c.json({ success: false, error: "Internal server error" }, 500);
}
});
Service (photo.service.ts) — the brain:
async searchByKeyword(request: SearchRequest): Promise<SearchResponse> {
const { keyword, limit = 20, offset = 0 } = request;
const photoIds = await this.repo.findPhotoIdsByKeyword(keyword, limit, offset);
const photos = await this.repo.findPhotosByIds(photoIds, limit, offset);
const photoRows = photos.map((photo) => ({ /* map DB row → domain PhotoRow */ }));
return { keyword, total: photoRows.length, photos: photoRows };
}
Notice the two-step query: first resolve which photo IDs match the keyword (via the keywords table), then fetch the full photo rows by those IDs. The service knows the workflow; it doesn't know SQL.
Repository (photo.repository.ts) — speaks only Drizzle:
async findPhotoIdsByKeyword(keyword, limit, offset): Promise<string[]> {
const rows = await this.db
.select({ photoId: unsplashKeywords.photoId })
.from(unsplashKeywords)
.offset(offset).limit(limit)
.where(like(unsplashKeywords.keyword, `%${keyword}%`));
return [...new Set(rows.map((r) => r.photoId))];
}
Why does this matter for developers? Because the layering makes the code navigable. Want to change the HTTP response shape? Edit the controller. Need a new business rule? It goes in the service. Swapping the database? Only the repository changes. Onboarding someone new means explaining five small files with clear jobs, not one tangled handler. The schema is even shared via the @welovephotos/validators package:
// packages/validators/src/search.ts
export const searchQuerySchema = z.object({
keyword: z.string().min(1).max(200),
limit: z.coerce.number().int().min(1).max(100).default(20),
offset: z.coerce.number().int().min(0).default(0),
});
Note the z.coerce.number() — query params arrive as strings, and Zod coerces them cleanly so the controller doesn't litter with parseInt.
9. The Shared Packages: Where the Monorepo Pays Off
Three packages knit the apps together:
@welovephotos/db— Drizzle ORM schemas for the five Unsplash Lite tables (photos,keywords,collections,conversions,colors) plus acreateDb(env)factory that instantiates the Turso libSQL client. The server imports it directly:import { createDb, unsplashPhotos, like, inArray } from "@welovephotos/db".@welovephotos/validators— the Zod schemas, shared so (in principle) both client and server validate against the same rules.@welovephotos/utils—cn(),chunks2Arr(),uniqueBy()— the little helpers that would otherwise get copy-pasted into every project.
This is the monorepo's quiet superpower: a change to the DB schema or a validation rule lands in one place and propagates to every app that depends on it.
Closing
"We Love Photos" is a compact but genuinely modern codebase: it leans on the right tool at each layer — pnpm + Turborepo for structure, Next.js static export + Vercel for the frontend, Hono + Bun + Cloudflare Workers for the API, TanStack Query for data, Blurhash for perception, and a clean DDD backend for maintainability. Read it top to bottom and you get a free tutorial in how these pieces compose in 2026. Copy the patterns, not the secrets. 📸
Source
Pleease take a look the open source repository* : https://github.com/agilworld/we-love-photos-v2 and land the page at https://welovephotos.dianragil.com